The most relevant description of this algorithm can be found in the paper “A subspace, interior and conjugate gradient method for large-scale bound-constrained minimization problems” by Coleman and Li, some insights on its implementation can be found in MATLAB documentation here and here. The difficulty was that the algorithm incorporates several ideas, but it was not very clear how to combine them all together in the actual code. I will describe each idea separately and then outline the algorithm in general. I will consider the algorithm applied to a problem with known Hessian, in least squares we replace it by 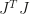
Interior Trust-Region Approach and Scaling Matrix
The minimization problem is stated as follows:

Some of the components of 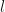





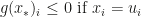

Define a vector 
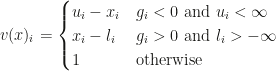
Its components are distances to the bounds at which anti-gradient points (if this distance is finite). Define a matrix 
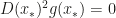

The Jacobian of the left hand side exist whenever 
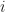

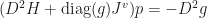
Here 


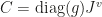
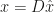
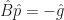

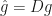

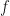
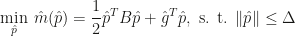
In the original space we have:

and the equivalent trust-region problem

From my experience the better approach is to solve the trust-region problem in “hat” space, so we don’t need to compute 
A modified improvement ratio of out trust-region solution is computed as follows:
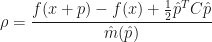
Based on 
Now summary and conclusion for this section. Motivated by the first-order optimality condition we introduced a matrix 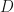
Reflective Transformation
This idea comes from another paper “On the convergence of reflective Newton methods for large-scale nonlinear minimization subject to bounds” by the same authors. Conceptually we apply a special transformation 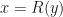
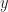

import numpy as np
def reflective_transformation(y, l, u):
if l is None:
l = np.full_like(y, -np.inf)
if u is None:
u = np.full_like(y, np.inf)
l_fin = np.isfinite(l)
u_fin = np.isfinite(u)
x = y.copy()
m = l_fin & ~u_fin
x[m] = np.maximum(y[m], 2 * l[m] - y[m])
m = ~l_fin & u_fin
x[m] = np.minimum(y[m], 2 * u[m] - y[m])
m = l_fin & u_fin
d = u - l
t = np.remainder(y[m] - l[m], 2 * d[m])
x[m] = l[m] + np.minimum(t, 2 * d[m] - t)
return x
This transformation is simple and doesn’t significantly increase the complexity of the function to minimize. But it is not differentiable when 
Large Scale Trust-Region Problem
In the previous post I conceptually described how to accurately solve trust-region subproblems arising in least-squares minimization. Here I again focus on least-squares setting and briefly describe how it can be solved approximately in large-scale.
- Steihaug Conjugate Gradient. Apply conjugate gradient method to the normal equation until the current approximate solution falls outside the trust region (or indefinite direction is found if
is rank deficient). This actually might be just the best approach for least squares as we don’t have negative curvature directions in
- Two-dimensional subspace minimization. We form a basis consisting of two “good” vectors, then solve two-dimensional trust region problem with the exact method. The first vector is a gradient, the second is an approximate solution of linear least squares with the current
Outline of Trust Region Reflective
Here is the high level description.
- Consider the trust-region problem in “hat” space as described in the first section.
- Find its solution by whatever method is appropriate (exact for small problems, approximate for large scale). Compute the corresponding solution in the original space
.
- Restrict this trust-region step to lie within bounds if necessary. Step back from the bounds by
times the step length. Do it for all type of steps below.
- Consider a single reflection of the trust-region step if bound was encountered in 3. Use 1-d minimization of the quadratic model to find the minimum along the reflected direction (this is trivial).
- Find the minimum of the quadratic model along the
- Choose the best step among 3, 4, 5. Compute the corresponding step in the original space as in 2, update
- Update the trust region radius by computing
- Check for convergence and go to 1 if the algorithm has not converged.
In the next two posts I will describe another type of algorithm which we call “dogbox” and provide comparison benchmark results.

Many thanks for your work. You are the only person i’m aware of that has attempted to explain the trust region reflective problem. Is your implementation the one that is currently used in scipy?
LikeLike
I’m glad that it is useful for you.
> Is your implementation the one that is currently used in scipy?
Yes, it’s one of the algorithms available in scipy.optimize.least_squares
Feel free to ask any questions you might have. I will try to check this blog from time to time.
LikeLike
Yes it was very helpful. Much more readable than academic papers. I’ve been attempting to do bounded least squares and this was the algorithm matlab uses so I was trying to learn it. However, when I carefully made my own implementation based upon this post, it seemed this algorithm was far overkill for bounded least squares.
The trust regions and reflection steps didn’t seem to be necessary. Perhaps if it was a bounded nonlinear function it would be necessary but not in the linear case. For a small scale case( n,m<100), a step of the following seemed to be fine:
p = -(D^2 * H + diag(g) * Jv)^(-1) * D^2 * g
So far for me, simply iterating based on these steps converged for a bounded least square problem generally in ~10 iterations. Prior to this, I was implementing an active set method that freezed the active bounds. However, this method was incredibly slow since only 1-2 bound could be identified per iteration and there may be 100s of active bounds.
I needed a javascript solution hence me investigating my own solver since I wasn't aware of an existing bounded least squares JS implementation. Anyhow, heres my simplified implementation based off your implementation: https://github.com/NateZimmer/Maths.js/blob/master/Solvers/lsqBounds.js
LikeLike
Yes, the full algorithm is necessary only for non-linear problems. The concept of a trust-region doesn’t really makes sense for a linear problem.
In fact I implemented also a solver for liner least squares with bounds, scipy.optimize.lsq_linear One of the algorithms it includes is a modification of trust-region-reflective (OK, “trust-region” is just a conventional name to make an analogy). Another one is a more well known “Bounded-Variable Least-Squares algorithm” (you can easily find a paper). It is more of a combinatorial algorithm and it doesn’t scale well for high dimensional problems, but for small problems is very good (it converges in a fixed number of steps in a very straightforward manner). So you might want to check that, implementation is available in scipy.
LikeLike